Introduction
One of my all-time favourite articles is The Law of Leaky Abstractions by Joel Spolsky. In the article, Joel explains how non-trivial abstractions that make software development more manageable often break. And when they do, we need to understand how they truly work so we can fix them quickly.
This is the reason I value learning from first principles. Over the years, I have often applied this learning style to learn more about the tools I use regularly. In this blog post, I will share my learnings on ArrayList, an implementation of List, by building a copy implementation from scratch.
Please note that we will not implement a production-grade implementation. Instead, we will focus on implementing the most commonly used list methods to get a feel for how they work and thus understand their use cases better.
Creating our custom ArrayList class
Let’s declare the initial skeleton of the implementation -
public class CustomArrayList<E> implements List<E> {
private Object[] elements;
public CustomArrayList() {
elements = new Object[?];
}
}
The official doc says that List implementations should support holding an arbitrary number of elements. However, we need to specify a size when creating the array. If we specify a large size, then we might waste memory. However, setting a shorter length puts a limitation on our capacity. So what do we do?
One way to get around this limitation is to create an array with a small capacity first and then resize it whenever we run out of space. Let’s go ahead and declare a 1-element array -
elements = new Object[1];
We could also consider passing the size during construction if we have a rough idea of how many elements we will store in this list. This would help us to initialise the array more efficiently as we would need less resizing. We could provide another constructor which would accept an initialCapacity as an argument and use it to initialise the array -
public class CustomArrayList<E> implements List<E> {
private Object[] elements;
public CustomArrayList() {
this(1);
}
public CustomArrayList(int initialCapacity) {
elements = new Object[initialCapacity];
}
}
This is why it’s always better to instantiate ArrayList using capacity if we know it in advance. It avoids unnecessary resizing.
Implementing methods
add(element)
We will implement the add method first, which is supposed to append the specified element to the end of this list -
@Override
public boolean add(E element) {
// If the insertion is successful, it should return true.
// Otherwise, it should return false.
// This method should never replace any existing elements.
return false;
}
Before appending the given element in the array, we need to know the next available position. We will define a new instance field, nextIndex, pointing to the next free slot in the array:
public class CustomArrayList<E> implements List<E> {
private Object[] elements;
// Contains 0 by default
private int nextIndex;
}
Once defined, let’s continue our add implementation -
@Override
public boolean add(E element) {
elements[nextIndex] = element;
nextIndex++;
return true;
}
How do we resize the array when it’s full? One way to do it is to create a new array, copy all the elements from the existing array, and then point elements to this new array:
@Override
public boolean add(E element) {
if (nextIndex == elements.length) {
Object[] copy = new Object[nextIndex + 1];
for (int i = 0; i < nextIndex; i++) {
copy[i] = elements[i];
}
elements = copy;
}
elements[nextIndex] = element;
nextIndex++;
return true;
}
What about performance? When we add a 2nd element to our list, we copy the existing element to the new array. On the 3rd add, the loop will copy two elements. Continuing like this, we can say that on N-th add, we will copy (N - 1) elements. To get the total number of copies required for the first N add, we sum them up = 1 + 2 + 3 + ... + (N - 1) = (N - 1) x N / 2.
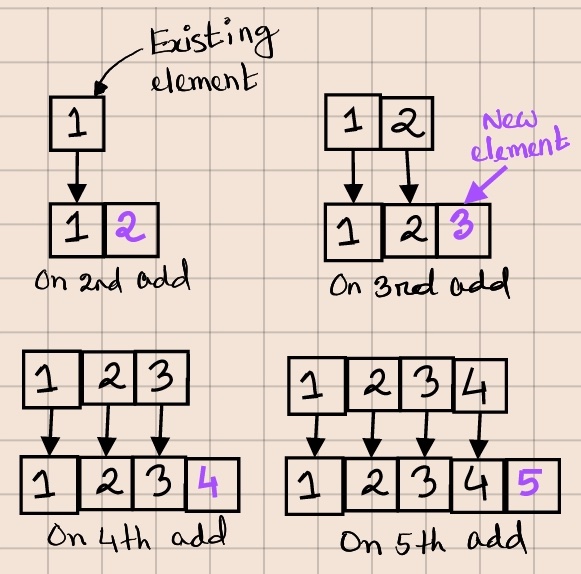
Adding the first N elements thus has an amortised time complexity of O(N^2). This means that if we double the size of the elements being added, the total time needed will increase 4-fold. Can we do better?
Thankfully, we can. Instead of increasing the capacity by one, we will double it:
@Override
public boolean add(E element) {
if (nextIndex == elements.length) {
Object[] copy = new Object[nextIndex * 2];
for (int i = 0; i < nextIndex; i++) {
copy[i] = elements[i];
}
elements = copy;
}
elements[nextIndex] = element;
nextIndex++;
return true;
}
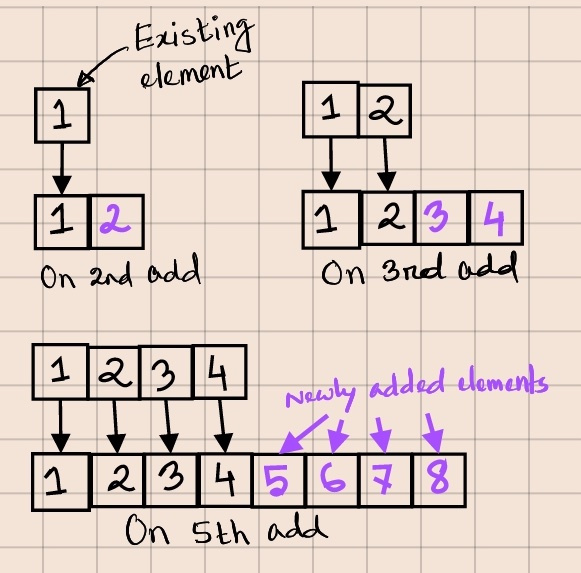
The amortised time complexity will now reduce to O(N). Like before, the 2nd add will copy one element. But before the 3rd add, our implementation will double the size of the elements array, so the 4th add won’t need to resize it again. The 5th add will again double the capacity and copy the existing 4 elements, but then the 6th, 7th, and 8th calls won’t trigger a resize.
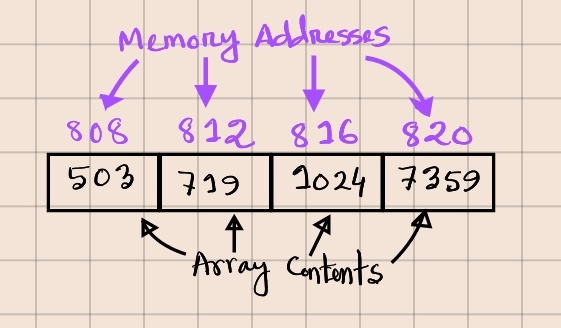
We can improve the actual performance even further by acknowledging a property of arrays called Data Locality. Data Locality guarantees that array elements are always stored in consecutive memory locations.
So rather than copying one element at a time, how about we copy blocks of memory instead? The System class has one such method, arraycopy, which we can use for this purpose:
@Override
public boolean add(E element) {
if (nextIndex == elements.length) {
Object[] copy = new Object[nextIndex * 2];
System.arraycopy(elements, 0, copy, 0, nextIndex);
elements = copy;
}
elements[nextIndex] = element;
nextIndex++;
return true;
}
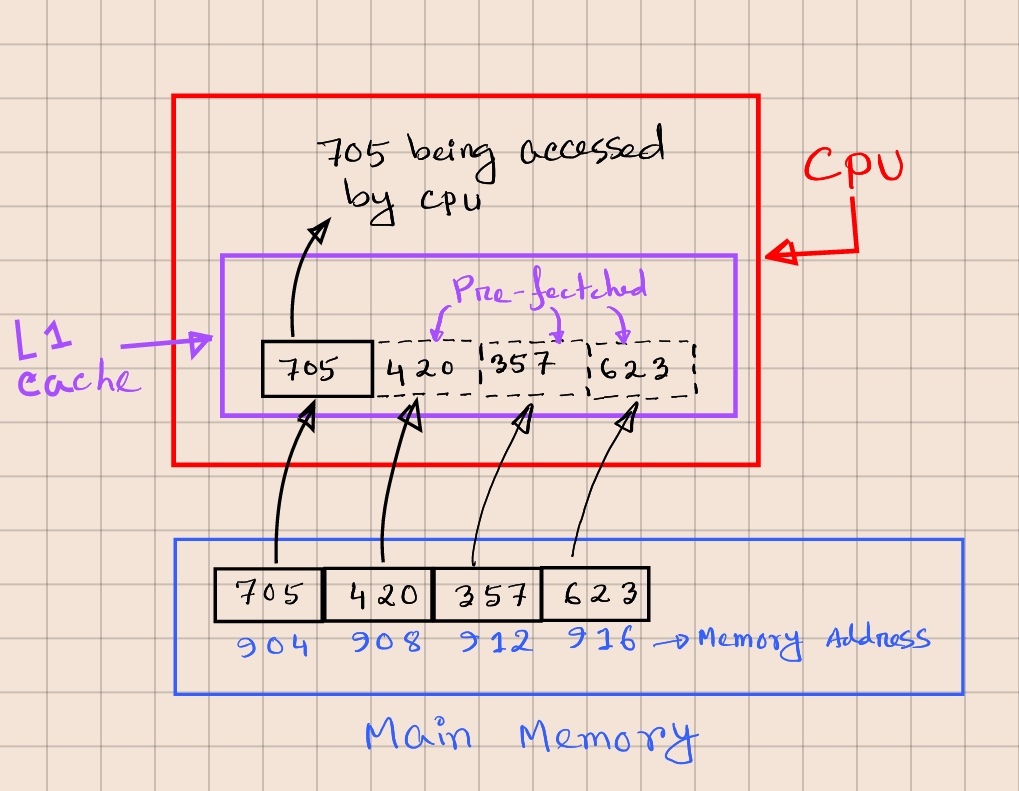
We can better understand the performance boost by looking at approximate latency numbers from this chart. As we can see, reading ~1MB of sequential data from main memory takes about ~1 microsecond. On the other hand, a random main memory reference takes about 100 nanoseconds. This shows that reading 10 elements from random memory locations would take roughly the same time as reading 1MB of sequential data.
Moreover, the CPU will likely have an L1 (and maybe L2) cache. When the OS fetches an array element from the main memory to the L1 cache, it’s likely to prefetch and store the elements at the following indexes, improving the performance even further.
Notice how we make a conscious trade-off between memory and running time when we double the array. This is fine if memory is available and cheap, which is usually the case. If not, we need a different strategy (i.e., increase the length by 25% or 50%).
size()
Next, we will implement the size method, which returns the number of elements in the list. The way we used nextIndex in our add method, it will always be equal to the size of the list:
@Override
public int size() {
return nextIndex;
}
remove(index)
Next up, the remove method -
@Override
public E remove(int index) {
/*
* Specification: if the index is out of bound, then throw
* IndexOutOfBoundsException.
*/
if (index < 0 || index >= nextIndex) {
throw new IndexOutOfBoundsException(
"index " + index + " is out of range"
);
}
}
If index is the last element in the elements array, we could decrement nextIndex by one so that the next insertion will overwrite the element at index nextIndex - 1:
@Override
public E remove(int index) {
/*
* Specification: if the index is out of bound, then throw
* IndexOutOfBoundsException.
*/
if (index < 0 || index >= nextIndex) {
throw new IndexOutOfBoundsException(
"index " + index + " is out of range"
);
}
if (index == nextIndex - 1) {
nextIndex--;
return elements[nextIndex];
}
}
Unfortunately, this implementation suffers from a memory leak. Let me explain why.
Suppose we have a list object with 10,000 elements and would like to remove each element one by one from the end without adding any new ones. In that case, nextIndex will keep decreasing, but the references to all these removed objects will still be in the array, preventing garbage collection.
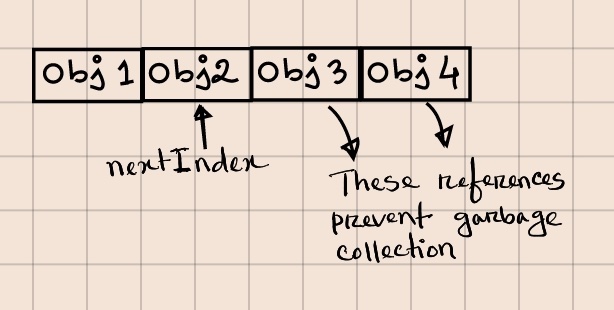
To prevent memory leak, we need to explicitly clear the reference by setting it to null:
@Override
public E remove(int index) {
/*
* Specification: if the index is out of bound, then throw
* IndexOutOfBoundsException.
*/
if (index < 0 || index >= nextIndex) {
throw new IndexOutOfBoundsException(
"index " + index + " is out of range"
);
}
if (index == nextIndex - 1) {
nextIndex--;
E elementBeingRemoved = (E) elements[index];
elements[nextIndex] = null;
return elementBeingRemoved;
}
}
To remove elements from any other position in the array, we can shift all elements starting from index one position to the left and then decrement nextIndex:
@Override
public E remove(int index) {
/*
* Specification: if the index is out of bound, then throw
* IndexOutOfBoundsException.
*/
if (index < 0 || index >= nextIndex) {
throw new IndexOutOfBoundsException(
"index " + index + " is out of range"
);
}
if (index == nextIndex - 1) {
nextIndex--;
E elementBeingRemoved = (E) elements[index];
elements[nextIndex] = null;
return elementBeingRemoved;
}
E elementBeingRemoved = (E) elements[index];
nextIndex--;
for (int i = index; i < nextIndex; i++) {
elements[i] = elements[i + 1];
}
elements[nextIndex] = null;
return elementBeingRemoved;
}
We can combine these two cases:
@Override
public E remove(int index) {
/*
* Specification: if the index is out of bound, then throw
* IndexOutOfBoundsException.
*/
if (index < 0 || index >= nextIndex) {
throw new IndexOutOfBoundsException(
"index " + index + " is out of range"
);
}
E elementBeingRemoved = (E) elements[index];
nextIndex--;
for (int i = index; i < nextIndex; i++) {
elements[i] = elements[i + 1];
}
elements[nextIndex] = null;
return elementBeingRemoved;
}
We can also leverage the Data Locality property here by copying elements by blocks. We will use the same System.arraycopy method, where both our source and destination will be the same array. The JavaDoc of System.arraycopy says -
If the src and dest arguments refer to the same array object, then the copying is performed as if the components at positions
srcPosthroughsrcPos + length - 1were first copied to a temporary array withlengthcomponents and then the contents of the temporary array were copied into positionsdestPosthroughdestPos + length - 1of the destination array.
To understand how the copy within the same array will work, notice that we move the element at index index + 1 to index, index + 2 to index + 1, and then finally, the element at index nextIndex to index nextIndex - 1. This implies that we specify index + 1 as the source index when doing block copy, as that’s the first element we copy. We specify index as our destination index as that’s where the first element finally moves to. nextIndex - index will give us the number of elements that need to be copied, as shown by the image below:
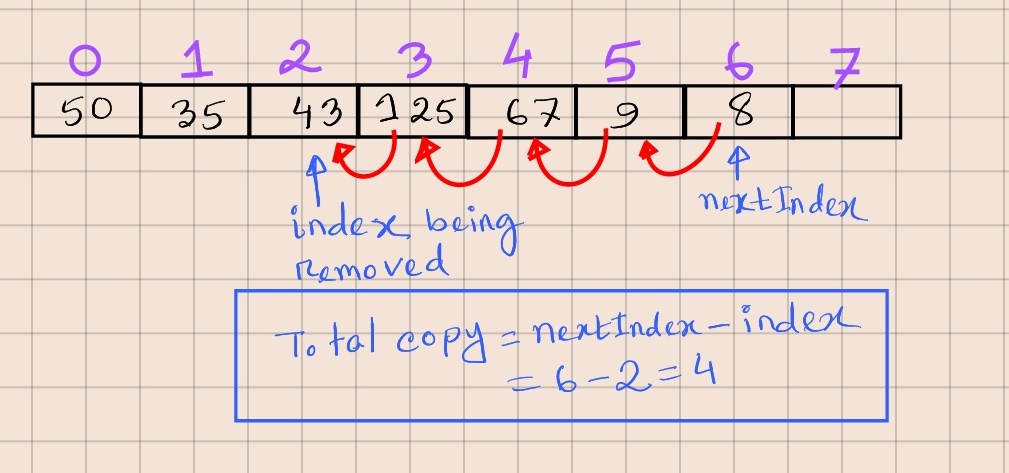
Let’s go ahead and refactor our method -
@Override
public E remove(int index) {
/*
* Specification: if the index is out of bound, then throw
* IndexOutOfBoundsException.
*/
if (index < 0 || index >= nextIndex) {
throw new IndexOutOfBoundsException(
"index " + index + " is out of range"
);
}
E elementBeingRemoved = (E) elements[index];
nextIndex--;
System.arraycopy(elements, index + 1,
elements, index, nextIndex - index);
elements[nextIndex] = null;
return elementBeingRemoved;
}
We can also resize and reduce the array size similar to the add method above. I leave it up as a fun exercise for the reader.
add(index, element)
Next method is add(index, element):
public void add(int index, E element) {
/*
* Specification: if the index is out of bound, then throw
* IndexOutOfBoundsException.
*
* Notice the difference with the index check of the
* `remove` method.
*/
if (index < 0 || index > nextIndex) {
throw new IndexOutOfBoundsException(
"index " + index + " is out of range"
);
}
/*
* If the index == nextIndex, we can leverage the `add`
* method to add the element at the end.
*/
if (index == nextIndex) {
add(element);
return;
}
}
The initial version implements the relatively more straightforward cases - when the index is out of bounds and when we insert the element at the end of the list. To finish the implementation, we need to consider two additional cases - when we don’t have enough space and need to resize the array and where we have enough space.
To handle the first case, we will resize the array as we did for add. Once resized, we will copy the first index number of elements to this new array, add the element at the given index, and then copy the rest of the elements to the new array -
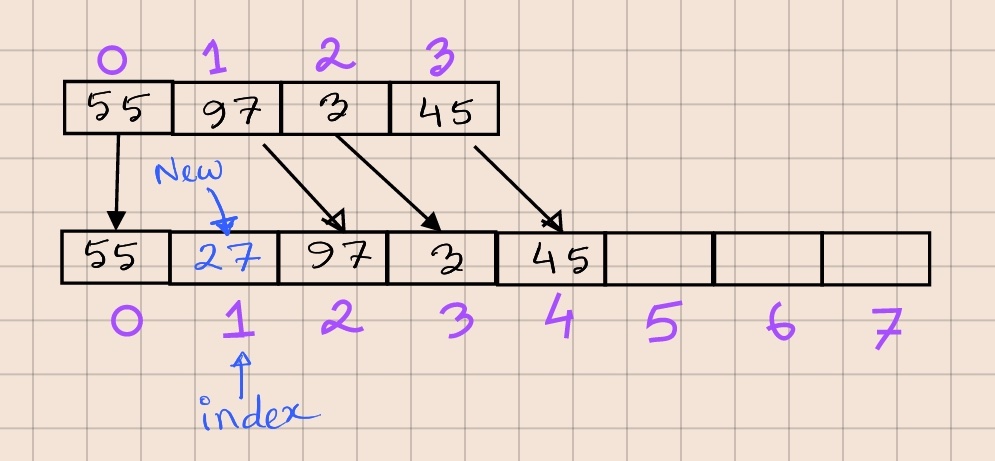
To handle the second case, we first shift all elements from the given index and then insert the new element at the index position. The code for both these cases are given below:
@Override
public void add(int index, E element) {
/*
* Specification: if the index is out of bound,
* then throw IndexOutOfBoundsException.
*
* Notice the difference with the index check of the
* `remove` method.
*/
if (index < 0 || index > nextIndex) {
throw new IndexOutOfBoundsException(
"index " + index + " is out of range"
);
}
/*
* If the index == nextIndex, we can leverage the `add`
* method to add the element at the end.
*/
if (index == nextIndex) {
add(element);
return;
}
if (nextIndex == elements.length) {
Object[] copy = new Object[nextIndex * 2];
System.arraycopy(elements, 0, copy, 0, index);
copy[index] = element;
System.arraycopy(elements, index,
copy, index + 1, nextIndex - index);
elements = copy;
} else {
System.arraycopy(elements, index,
elements, index + 1, nextIndex - index);
elements[index] = element;
}
nextIndex++;
}
contains(element)
This implementation is relatively straightforward. We do a linear scan through the elements array from left to right, checking for object equality to see if the given element exists in the array:
@Override
public boolean contains(Object element) {
for (int i = 0; i < nextIndex; i++) {
if (Objects.equals(elements[i], element)) {
return true;
}
}
return false;
}
Or we can use streams:
@Override
public boolean contains(Object element) {
return Arrays.stream(elements)
.limit(size())
.anyMatch(existingElement ->
Objects.equals(existingElement, element));
}
remove(element)
We can leverage the existing remove(index) method to implement removal by element. To do that, we do a linear scan of our elements array, find the index of the element, and then call remove(index):
@Override
public boolean remove(Object element) {
for (int i = 0; i < nextIndex; i++) {
if (Objects.equals(elements[i], element)) {
remove(i);
return true;
}
}
return false;
}
iterator()
We will implement a simplified version of the iterator, which will not check for concurrent modification and will not allow removal via the iterator.
We will write a custom Iterator, which will take a snapshot of our list’s size() and then continue iterating until we all elements have been returned:
private class CustomArrayListIterator implements Iterator<E> {
private final int size = CustomArrayList.this.size();
private int index = 0;
@Override
public boolean hasNext() {
return index < size;
}
@Override
public E next() {
return (E) elements[index++];
}
}
@Override
public Iterator<E> iterator() {
return new CustomArrayListIterator();
}
When to use an array-backed list?
Now that we have seen how an array-based list implementation works, when should we use them? And when should we avoid using them?
As a rule of thumb - I always prefer using
ArrayListover other list implementations likeLinkedList. In almost all cases, a linked list based-implementation will lose out to ArrayList in terms of performance. The performance boost from Data Locality combined with sequential memory block copy and Prefetching in L1 and/or L2 cache is hard to beat.
There is a particular scenario where LinkedList may perform better than ArrayList. When we constantly need to add and/or remove elements from the beginning of the list (or anywhere before the midpoint of the list) AND the list contains millions and millions of objects, then a LinkedList may provide better performance. Even then, I recommend performing a benchmark/load test to see if the ArrayList is the bottleneck.
Conclusion
I hope you enjoyed reading the article. In future posts of the Unwinding the Abstraction series, I hope to demystify more tools and share the learnings with you all.
The sample implementation used in this article is available at Github.
Acknowledgements
Many thanks to Nur Bahar Yeasha for proofreading a draft version of this article and suggesting corrections and improvements.